Hi there, I'm Aleksei Petrenko

Making computers do things at which, at the moment, people are better. (Rich and Knight, 1991)
I am a research scientist at Apple, working on autonomous systems.
I received my PhD in Computer Science in 2023 from the University of Southern California
I was a part of Robotics and Embedded Systems Lab and was advised by
prof. Gaurav Sukhatme.
My research focus is deep reinforcement learning and simulation for robotics and embodied AI.
During my PhD I worked at NVIDIA on high-throughput simulation and RL for robots, at Intel
on massively parallel 3D rendering and high-throughput reinforcement learning.
Before going to academia I spent 8 years in industry, working on software R&D, machine learning, algorithms, 3D graphics, computer vision, and virtual reality.
Research interests
I study computationally efficient methods of training agents in simulation using reinforcement learning, as well as problems of sim-to-real transfer. Recently I've been working on:
- Highly optimized open-source software for deep reinforcement learning, such as RL algorithms and simulators.
- Advanced training scenarios such as population-based training and self-play.
- Reinforcement learning in robotics: dexterous manipulation and quadrotor swarms.
Recent publications:
2022:-
A Petrenko, A Allshire, G State, A Handa, V Makoviychuk.
DexPBT: Scaling up Dexterous Manipulation for Hand-Arm Systems with Population Based Training.
Submitted to RSS 2023.
Large-scale reinforcement learning for high-DoF hand-arm systems. -
A Handa*, A Allshire*, V Makoviychuk*, A Petrenko*, R Singh*, J Liu*, D Makoviichuk, K Van Wyk, A Zhurkevich, B Sundaralingam, Y Narang, J Lafleche, D Fox, G State.
DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality.
In ICRA 2023.
[Paper] [Website]
Learning dexterous in-hand manipulation in vectorized simulation and deploying policies on the real robot.
-
A Petrenko, E Wijmans, B Shacklett, V Koltun.
Megaverse: Simulating Embodied Agents at One Million Experiences per Second.
In ICML2021.
[Paper] [Code] [Website]
The fastest (at the time of release) embodied simulator for AI research. 1,000,000+ FPS of immersive experience on a single machine.

-
S Batra*, Z Huang*, A Petrenko*, T Kumar, A Molchanov, G Sukhatme.
Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement Learning.
In CORL2021.
[Paper] [Code] [Website] End-to-end learning of neural policies for quadrotor swarms with sim-to-real transfer.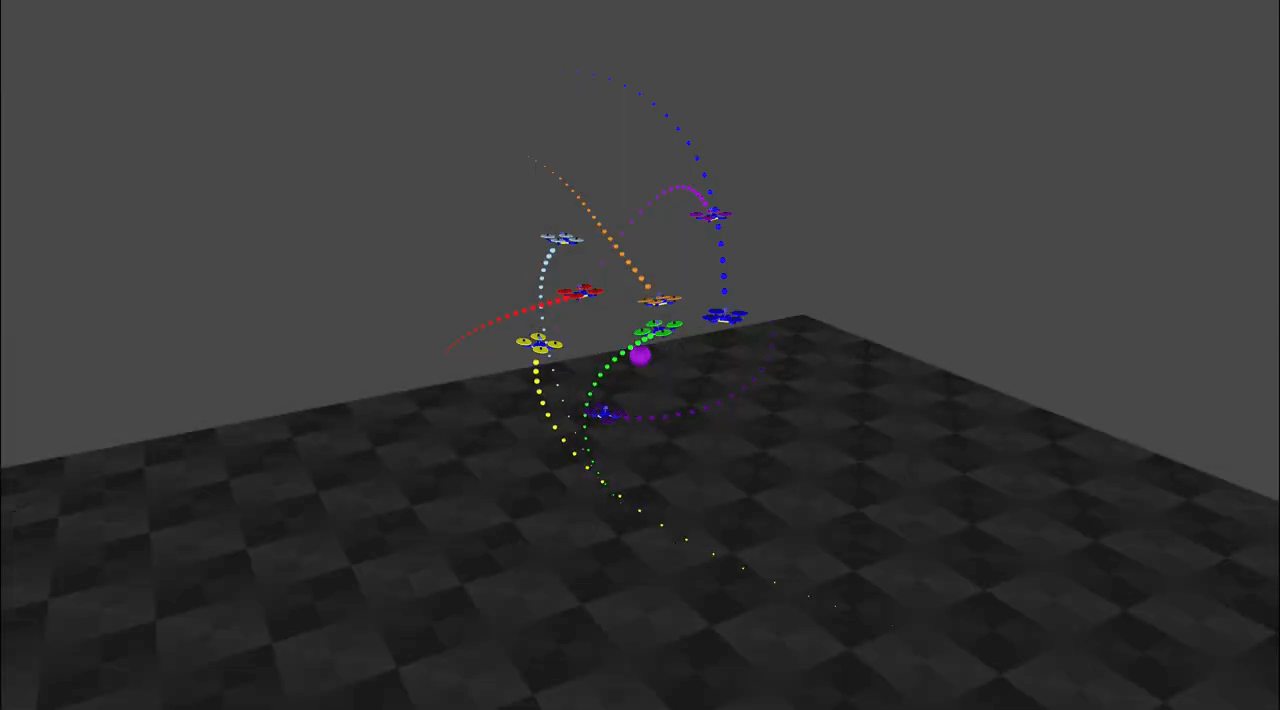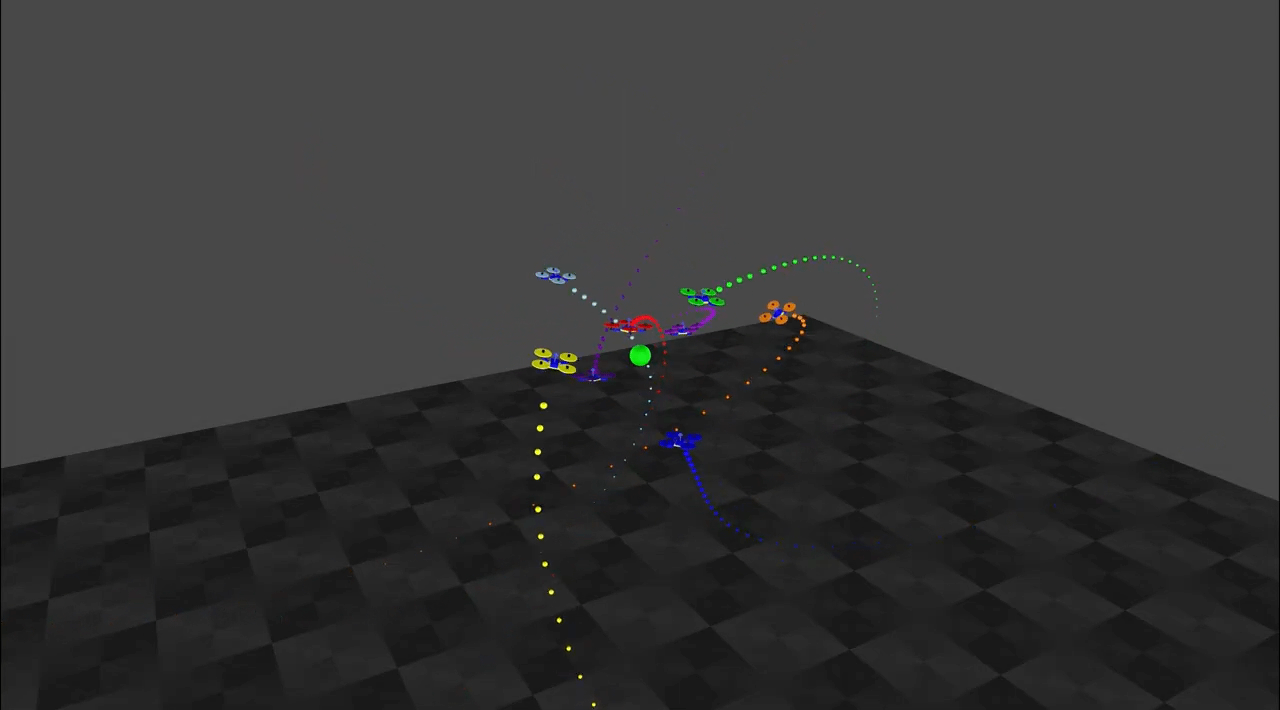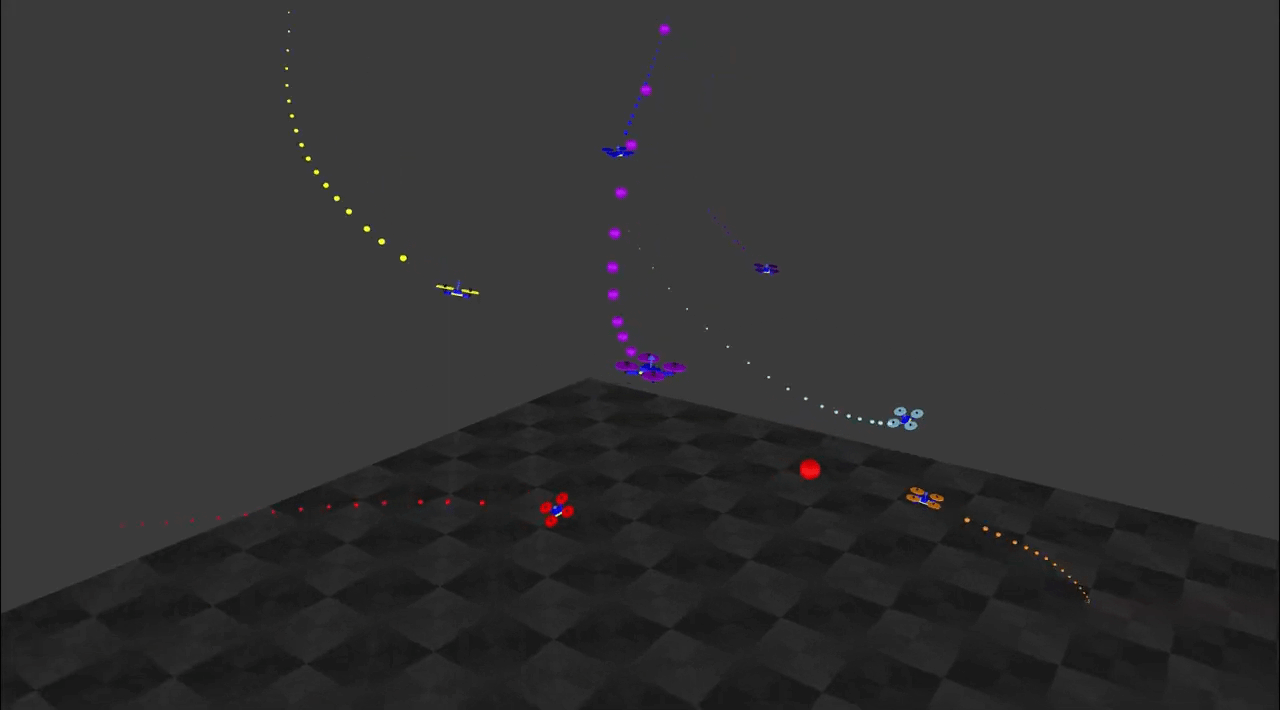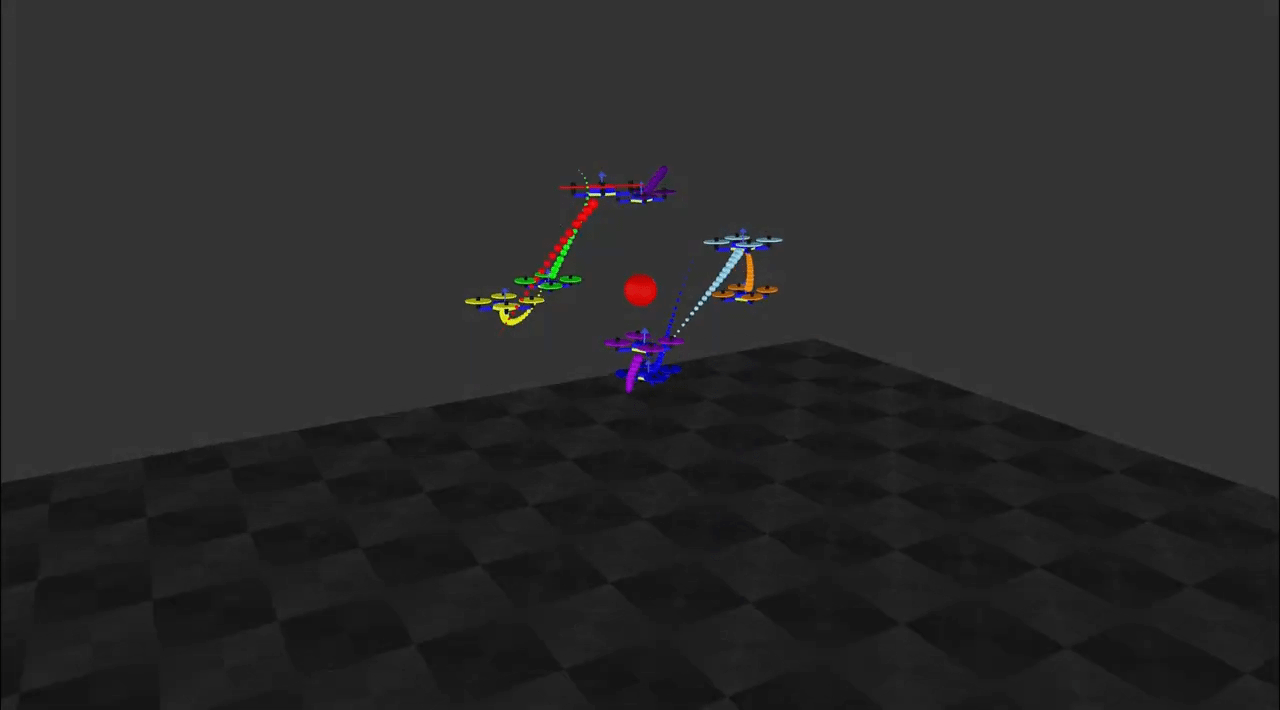
-
S Hegde, A Kanervisto, A Petrenko.
Agents that Listen: High-Throughput Reinforcement Learning with Multiple Sensory Systems.
In IEEE Conference on Games, 2021.
[Paper] [Code] [Website] -
B Shacklett, E Wijmans, A Petrenko, M Savva, D Batra, V Koltun, K Fatahalian.
Large Batch Simulation for Deep Reinforcement Learning.
In ICLR2021.
[Paper] [Code]
-
A Petrenko, Z Huang, T Kumar, G Sukhatme, V Koltun.
Sample Factory: Egocentric 3D Control from Pixels at 100000 FPS with Asynchronous Reinforcement Learning.
In ICML2020.
[Paper] [Code] [Website] [Talk]
[Press #1] [Press #2] [Press #3] [Press #4]
Reinforcement learning framework with the highest single-machine training throughput at the time of publication, ~10x faster than traditional synchronous RL implementations. SOTA results in challenging VizDoom and DMLab environments.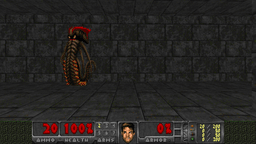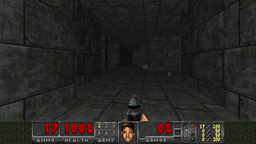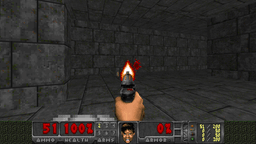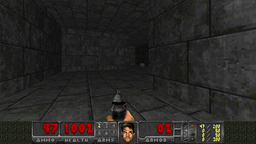

Selected open-source projects:
-
https://github.com/alex-petrenko/sample-factory
High-throughput asynchronous reinforcement learning framework. -
https://github.com/alex-petrenko/megaverse
Embodied simulation for RL research at 1,000,000 FPS. -
https://github.com/alex-petrenko/faster-fifo
A faster alternative to built-in Python multiprocessing.Queue. -
https://github.com/alex-petrenko/signal-slot
Python implementation of Qt-like signal & slot asynchronous programming paradigm with focus on multiprocessing applications. -
github.com/alex-petrenko/tf-reinforce
Tensorflow implementation of classic policy gradient algorithm for continuous control tasks -
github.com/alex-petrenko/snake-rl
RL algorithms for classic Snake game (youtube) -
hyperopt.py
Evolutionary algorithm for hyperparameter optimization in deep learning (it works!) -
github.com/alex-petrenko/udacity-linear-algebra-cpp
Small linear algebra library in C++11/14 with templates, SFINAE, etc.
Other research projects:
Curiosity-driven Exploration in RL (2018)
github.com/alex-petrenko/curious-rlTensorflow implementation of the method "Curiosity-driven Exploration by Self-supervised Prediction" by Pathak et al. for hard exploration tasks in 3D pixel-based environment.


RL agents for a game "MicroTbs" (2017)
github.com/alex-petrenko/rl-experimentsAn OpenAI Gym-compatible 2D environment and some RL algorithms trained in it: Double DQN, A2C, etc. Inspired by an old game Heroes of Might and Magic III, which is quite challenging for contemporary AI. I designed this environment to resemble some of the features of the original game: scouting, different terrain, picking up resources, etc. A sample video (more in the repository):
{kind=link}
Capturing volumetric video (2017)
github.com/alex-petrenko/4dvideo
"4D video" grabber and player for Intel RealSense and Google Tango.
The player is based on modified Guibas-Stolfi triangulation algorithm and can generate 3D mesh in realtime (300fps on PC, 100fps on Android).
With this software I captured a lot of cool 4D clips:
I also made some algorithm visualizations for fun, check 'em out!
Industry and applied research:
itSeez3D: Avatar SDK (2016-2018)
At itSeez3D I worked on a very interesting project called AvatarSDK. AvatarSDK is a deep-learning based pipeline for human digitization. Check out some of my digital copies automatically generated by our system (and a bonus):
itSeez3D: Mobile 3D scanner (2013-2017)
With itSeez, and later itSeez3D I participated in the development of the 3D scanning software for various structured light sensors. Our results are close to those of professional 3D scanners, for 10-100x less money! Hey, this page needs more Sketchfab embeds:
Let's get in touch!